1
2
3
4
start transaction;
insert into goods values('item1', 1000);
insert into goods values('item2', 1100);
commit;
Spring Transaction에 대한 노트
목차
1. 개요
이 문서는 Spring 기반의 트랜잭션 관리에 대해 기본지식 및 가이드를 제공하기 위한 문서입니다.
개념 전달을 위해 과도한 일반화 및 단순화된 문서이므로 테크니컬하게 정확성을 제공하지는 않습니다.
2. TLDR; (Too long, Didn’t read)
-
Exception은 Rollback 되지 않습니다. RuntimeException이여야 rollback됩니다.
-
Bean이 자기 자신의 메소드를 호출하면 Transaction 어노테이션을 처리 못합니다. Proxy 된 객체를 얻어서 호출하세요
-
다수의 Datasource를 사용할때 TxManager에 일치하는 데이터 소스만 사용하세요
-
Global Tx 가 적용된 Datasource들이라면 섞어서 사용 가능합니다
3. Transaction이란?
3.1. Unit of Work
트랜잭션이라 하나의 논리적 작업 단위로 수행되는 일련의 작업 을 말합니다.
일련의 작업이 모두 하나의 논리적 작업으로 취급되기 때문에 논리적 작업을 취소하면, 그 내부에 포함된 일련의 작업들이 모두 취소됩니다. 물론 논리적 작업을 완료하면 내부에 포함된 일련의 작업들이 모두 완료되게 됩니다. 일련의 작업 논리적 작업이 종료 되어야만 완료/취소 됩니다.
디자인 패턴등에서는 작업 단위( Unit Of Work )로 설명되기도 합니다.
3.2. ACID
트랜잭션이 가져야 하는 특성에는 ACID이 있습니다.
-
Atomicity: 원자성은 트랜잭션과 관련된 작업들이 부분적으로 실행되다가 중단되지 않는 것을 보장하는 능력이다. 예를 들어, 자금 이체는 성공할 수도 실패할 수도 있지만 보내는 쪽에서 돈을 빼 오는 작업만 성공하고 받는 쪽에 돈을 넣는 작업을 실패해서는 안된다. 원자성은 이와 같이 중간 단계까지 실행되고 실패하는 일이 없도록 하는 것이다.
-
Consistency: 일관성은 트랜잭션이 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 유지하는 것을 의미한다. 무결성 제약이 모든 계좌는 잔고가 있어야 한다면 이를 위반하는 트랜잭션은 중단된다.
-
Isolation: 고립성은 트랜잭션을 수행 시 다른 트랜잭션의 연산 작업이 끼어들지 못하도록 보장하는 것을 의미한다. 이것은 트랜잭션 밖에 있는 어떤 연산도 중간 단계의 데이터를 볼 수 없음을 의미한다. 은행 관리자는 이체 작업을 하는 도중에 쿼리를 실행하더라도 특정 계좌간 이체하는 양 쪽을 볼 수 없다. 공식적으로 고립성은 트랜잭션 실행내역은 연속적이어야 함을 의미한다. 성능관련 이유로 인해 이 특성은 가장 유연성 있는 제약 조건이다. 자세한 내용은 관련 문서를 참조해야 한다.
-
Durability: 지속성은 성공적으로 수행된 트랜잭션은 영원히 반영되어야 함을 의미한다. 시스템 문제, DB 일관성 체크 등을 하더라도 유지되어야 함을 의미한다. 전형적으로 모든 트랜잭션은 로그로 남고 시스템 장애 발생 전 상태로 되돌릴 수 있다. 트랜잭션은 로그에 모든 것이 저장된 후에만 commit 상태로 간주될 수 있다.
이런 특성은 당연히 전체적인 성능에 지대한 영향을 미치게 되며 성능 확장성을 제한합니다. 따라서 고성능이 필요한 곳에서는 트랜잭션을 배제하고 설계할 필요가 있습니다.
하루에 10억건이상의 비니지스가 발생하는 이베이에서는 트랜잭션을 사용하지 않게 설계 되어 구동합니다.
4. Transaction In SQL
Commit 또는 Rollback
5. Transaction in JDBC
5.1. Transaction Script Example
Java에서 JDBC 표준에 따라 DB 연동에 대한 프로그래밍은 생각보다 할수 있는게 별로 없습니다.
Connection을 얻어오고, Statement를 만들어 SQL을 실행한후, 정리작업을 하는것이 전부라고 할수 있습니다.
5.1.1. 단일 작업
1
2
3
4
5
6
7
8
9
Connection conn = Driver.getConnection("url","id","pw");
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("select * from goods");
while(rs.next()) {
log.info("Goods: {}", rs.getString("goods_name");
}
rs.close();
stmt.close();
conn.close();
5.1.2. 트랜잭션 작업
1
2
3
4
5
6
7
8
9
10
11
12
13
14
Connection conn = Driver.getConnection("url","id","pw");
conn.setAutoCommit(false);
Statement stmt1 = conn.createStatement();
ResultSet rs = stmt1.executeQuery("select * from goods");
while(rs.next()) {
PraparedStatement stmt2 = conn.createPreparedStatement();
stmt2.execute("insert into goods_name_list values (?,?)", rs.getString("name"), rs.getString("label"));
stmt2.close();
}
rs.close();
stmt.close();
conn.commit();
conn.close();
5.2. Multi method transaction example
업무가 복잡해짐에 따라 단일 메소드에 에 모든 내용을 기술하기 어려워 집니다. 업무를 작게 나누어 개별 메소드에서 실행하고자 할때 새로운 문제가 발생합니다.
바로 Connection을 관리하고 전파 해야 한다는 것입니다.
(샘플 코드에서 복잡한 로직을 나타내기 어려움이 있습니다. 복잡한 로직이라고 상상해주세요 ^^)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
public void recordGoodNameList(String type) {
Connection conn = Driver.getConnection("url","id","pw");
conn.setAutoCommit(false);
try {
List<String> names = findGoodsNames(conn, type);
saveGoodsNames(conn, name);
conn.commit();
}catch(Exception ex){
conn.rollback();
}
finally {
conn.close();
}
}
public List<String> findGoodsNames(Connection conn, String type) {
List<String> res = new ArrayList<>();
Statement stmt1 = conn.createStatement();
ResultSet rs = stmt1.executeQuery("select * from goods where type="+type);
while(rs.next()) {
res.add(rs.getString("name"));
}
rs.close();
stmt1.close(); // <— 잠재적인 Close 버그 가 있음
return res;
}
public void saveGoodsNames(Connection conn, List<String> names) {
PreparedStatement stmt = conn.preparedStatememt("insert into goods_name_list(name) values (?)" );
for(String name: names) {
stmt.setString(1, name);
stmt.addBatch();
stmt.clearParameters();
}
stmt.executeBatch();
stmt.close();
}
Connection을 생성하고, 전파하는 문제도 복잡해지지만, 중복되는 오류 코드등이 많이 발생하게 됩니다.
5.3. Connection
JDBC에서 트랜잭션이란 결국, autoCommit 이 false 인 connection에 대해 여러 SQL을 실행시킨후에 마지막에 commit/rollback 하는 것이라고 할수 있습니다.
각 SQL에서 SQL을 실행하기 위해서는 connection에서 statement 객체를 얻어와야 하기 때문에 SQL을 실행 하고자 하는 곳에서는 항상 connection 객체가 필요합니다.
이런 과정에서는 에러 처리나 닫음 처리등 반복 되는 코드도 많습니다. 이 중에 어느 하나 누락되면 성능 문제나 정합성 문제가 발생 하게 됩니다.
분리된 트랜잭션등 앞서 기술되지 않은 복잡한 tx을 프로그래밍 해야 한다면 코딩 난이도는 엄청나게 상승하게 됩니다.
6. Transaction in Spring
6.1. AOP
스프링이 제공하는 이런 매직을 이해 하려면 AOP(Aspect Oriented Programming)에 대한 기본적인 지식이 필요합니다.
AOP 를 대략적이라도 이해하시는 분은 넘어가시면 됩니다 ^^
프로그래밍을 하다 보면 반복 되는 코드들이 나오게 됩니다. 이런 코드를 조직화 하는것이 프로그래밍 패러다임입니다.
6.1.1. 구조적 프로그래밍
구조적 프로그래밍은 함수/프로시져로 반복되는 코드를 구조화 하고 이런 함수/프로시져를 호출(call) 하는 것으로 재사용하는 패러다입니다.
원래 소스
1
2
3
int i = a1 + b1 * 2;
int j = a2 + b2 * 2;
int k = a3 + b3 * 2;
함수가 적용된 소스
1
2
3
4
5
6
int calc(int a, int b){
return a + b * 2;
}
int i = calc(a1 , b1);
int j = calc(a2, b2);
int k = calc(a3 , b3);
6.1.2. 객체지향 프로그래밍
객체 지향 프로그래밍은 구조적 프로그래밍에 기반을 두고 있지만, 주로 확장되는 동작을 구조화 하는데 촛점이 맞춰져 있습니다
원래 소스
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
function feed(enum animalType) {
switch(animalType) {
case HORSE:
feedGrain();return;
case LION:
FeedMeet(); return;
...
}
}
function training(enum animalType) {
switch(animalType) {
case HORSE:
trainRun();return;
case LION:
trainHunt(); return;
...
}
객체 지향이 적용된 소스
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
interface Animal {
Void feed();
Void training();
}
Class Horse extends Animal{
Void feed(){
... // Eat grain
}
void training() {
.. // run
}
}
Class Lion extends Animal{
Void feed(){
... // Eat meat
}
void training() {
.. // hunt
}
}
class Trainer {
void work() {
for(Animal animal: animals){
animal.feed();
}
for(Animal animal: animals){
animal. training();
}
}
(Note: 객체 지향 프로그래밍의 가장 큰 장점을 클래스 단위로 만들어지는 namespace 로 꼽는 경우도 많습니다)
6.1.3. 관점 지향 프로그래밍
앞서 나온 패러다임들은 호출 관계에 놓인 코드들을 구조화 하였습니다.
관점 지향 프로그래밍(Aspect Oriented Programming)은 시점에 따른 구조화를 수행하는 패러다임 입니다.
여기에서 시점이란 메소드를 호출하는 순간, 메소드가 값을 반환하는 순간, 클래스의 필드를 읽으려고 하는 순간, 클래스의 필드에 값을 쓰려고 하는 순간, 예외가 발생한 순간… 등 뭐라 정의 하기는 애매하지만 우리 모두 알고 있는 그 시점입니다. (Crosscutting concerns이라고 보통 이야기 하지만 crosscutting concerns에 대한 공통의 정의는 없습니다 ^^)
특정 시점을 정의하고 (Pointcut), 수행하려고 하는 작업을 정의하고(Advide) , 두 가지것이 묶인것을 관점(Aspect)라고 정의합니다.
6.2. Spring TransactionAdvisor 이해하기
AOP를 Spring Tx와 관련지어 설명하자면 다음과 같습니다
-
Pointcut:
@Transaction어노테이션을 가지고 있는 public 메소드에 진입하고 반환할때(Around pointcut) -
Advice: 트랜잭션 관리를 수행한다. (트랜잭션을 시작하고, 오류없이 반환되면 Commit,
RuntimeException이 발생하면 rollback) -
Aspect:
@Transaction어노테이션을 가지고 있는public메소드에 진입하고 반환할 때 트랜잭션 관리를 수행한다

그림에서 보듯이 Client 코드인 Controller에서 Component의 메소드를 호출하려는 순간에 끼어 들어 동작하게 됩니다.
그럼 Spring 의 TransactionAdvisor 는 어떤 동작을 할까요? (힌트: 결국에는 JDBC뿐입니다)
내부 코드가 어찌 되었든 할 수 있는 것은
-
Connection을 얻어오고 setAutoCommit(false)를 호출한 후에
-
Bean의 메소드를 호출한 후에,
-
정상적으로 반환되면 connection.commit()을 호출하고,
-
RuntimeException 이 발생하면 connection.rollback()을 호출합니다.
TransactionAdvice의 코드가 아무리 복잡해도 JDBC 기반에서 할 수 있는 게 이것뿐입니다.
하지만 트랜잭션을 실행시키는것과는 별도로, Connection을 관리하는 것 자체가 분리된 트랜잭션, 고립수준 변경, 복수의 데이터소스 관리등 다양한 이슈를 다뤄야 하기 때문에 난이도가 높은 작업입니다.
Spring Transaction Aspect을 이해 할때 중요한점은 몇가지가 있습니다.
6.2.1. Spring에 등록된 Bean에 대해서 적용되며 @Transactional 이 붙은 모든 public 메소드가 대상이라는 것입니다.
바꿔 말하면 Spring Bean으로 등록되지 않았거나 @Transactional이 붙지 않았거나 public 이 아닌 메소드는 대상이 아닙니다. 분리된 트랜잭션이나 고립수준 변경등을 트랜잭션과 관련된 작업을 수행하기 위해서는 Spring Bean이여야 하고 @Transactional이 붙은 public 메소드여야 합니다.
6.2.2. Rollback을 수행하는 기준은 RuntimeException/Error가 발생했을때입니다. 그냥 Exception이 발생하면 Commit 됩니다.
1
2
3
4
5
6
7
@Transactional
public void action(Goods goods) throws Exception {
InsertGoods(goods);
String xml = goods.getXml();
Goods nextGoods = parseXml(xml);
InsertGoods(nextGoods);
}
위의 코드에서 xml 파싱중에 XMLParserException이 발생하게 되면 어떻게 될까요? XMLParserException이 RuntimeException이 아니기 때문에 insert 된 내용을 그냥 커밋 됩니다.
프로그램은 오류를 내며 중지되었는데 DB에는 값이 커밋되는 문제가 발생하게 된거죠. 정합성에 문제가 발생하게 됩니다.
조금 당황 스럽죠.
Spring 개발진 내부에서도 Exception을 기본으로 할 것이냐 아니면 RuntimeException을 기본으로 할 것이냐에 대해 치열한 토론이 있었답니다.
| Spring Transaction 설계 사상 자체가 하부 라이브러리의 오류를 DataAccessException등 RuntimeException으로 래핑하여 처리하는 등 RuntimeException을 기반으로 설계하였기 때문에 갑자기 등장하는 Exception으로 설계 사상에 대한 혼란이 발생할 수 있어서 최소 놀람의 원칙에 의해 RuntimeException로 최종 결정되었다고 합니다. |
이 문제에 대한 해결책은 몇가지가 있습니다.
메소드 뒤에 throws Exception이 붙지 않게 한다
Exception(일명 Checked Exception)은 문법적으로 throws 를 강요합니다.
throws 가 붙어야 한다면 try catch 로 감싸서 RuntimeException으로 변환해서 다시 던집니다.
1
2
3
4
5
6
7
8
@Transactional
public void action(){
try {
ParseXml();
} Catch (Exception ex) {
throw new RuntimeException(e);
}
}
Rollback기준을 Exception이나 Throwable 로 높힌다
1
2
3
4
@Transactional(rollbackFor=Exception.class)
public void action() throws Exception {
ParseXml();
}
Spring AOP는 Proxy 기반으로 별도의 객체가 Bean을 호출하는 방식이 기본입니다.
Client가 대상 Bean의 메소드를 호출할때 중간에 Proxy 객체가 그 메시지를 대신 받아서 트랜잭션을 실행시키고 bean의 메소드를 실행시키는 것인데요…
Bean 객체 생성되면 Bean 객체는 Aspect Proxy 객체에 쌓여서 다른 Client에 주입되어 사용되게 됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class Service {
@Transactional public void save(){...};
}
class Client {
@Autowired Service service;
public void action() {
service.save();
}
}
위에서 Client는 주입된 service의 action()을 호출하지만, 실제로는 Spring AOPProxy객체의 save() 를 호출하게 됩니다.
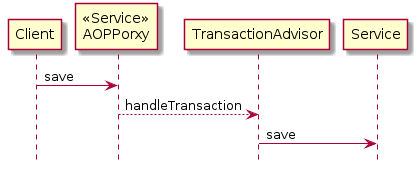
뭐 위의 경우는 큰 문제가 없습니다
하지만 다음처럼 Bean이 자신의 메소드를 호출할때 문제가 발생합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
class Service {
public void action() {
save();
}
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void save() {
saveA();
saveB();
saveC();
}
}
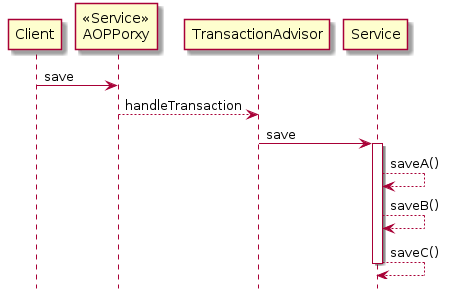
이럴경우 @Transaction을 읽고 해석하여 동작시켜줄 proxy를 거치지 않고, 그냥 Bean 자신의 메소드를 호출하는 것입니다. 그러니 트랜잭션으로 동작하지 않고, 단일 SQL이 실행될때마다 commit 될것입니다. SaveC()를 호출하다 오류가 발생해도 A,B는 이미 커밋이 된 상태겠지요.
이런 문제를 해결하는 방법은 3가지 정도가 일반적 입니다.
Bean 스스로를 주입 받는다
1
2
3
4
5
@Component
class Service {
@Autowired Service proxiedService;
Public void actionA() { proxiedService.save(); }
}
이 해결법은 가끔 Bean 초기화 과정에서 Proxied가 아닌 오리지널 Bean이 주입되는 경우가 있기 때문에 테스트를 잘 해야 합니다.
Bean을 분리한다.
1
2
3
4
5
@Component
class ServiceA {
@Autowired ServiceB delegate;
Public void action() { delegate.save(); }
}
ApplicationContext를 이용한다
1
2
3
4
5
6
7
@Component
Class Service {
@Autowired ApplicationContext ctxt;
Public void action(){
ctxt.getBean(Service.class()).save();
}
}
6.3. Transaction Manager 이해하기
앞에서 Connection을 관리 하는것이 난이도가 높다고 기술했었죠. 이 복잡한 책임을 수행하는 클래스는 PlatformTransactionManager 입니다.
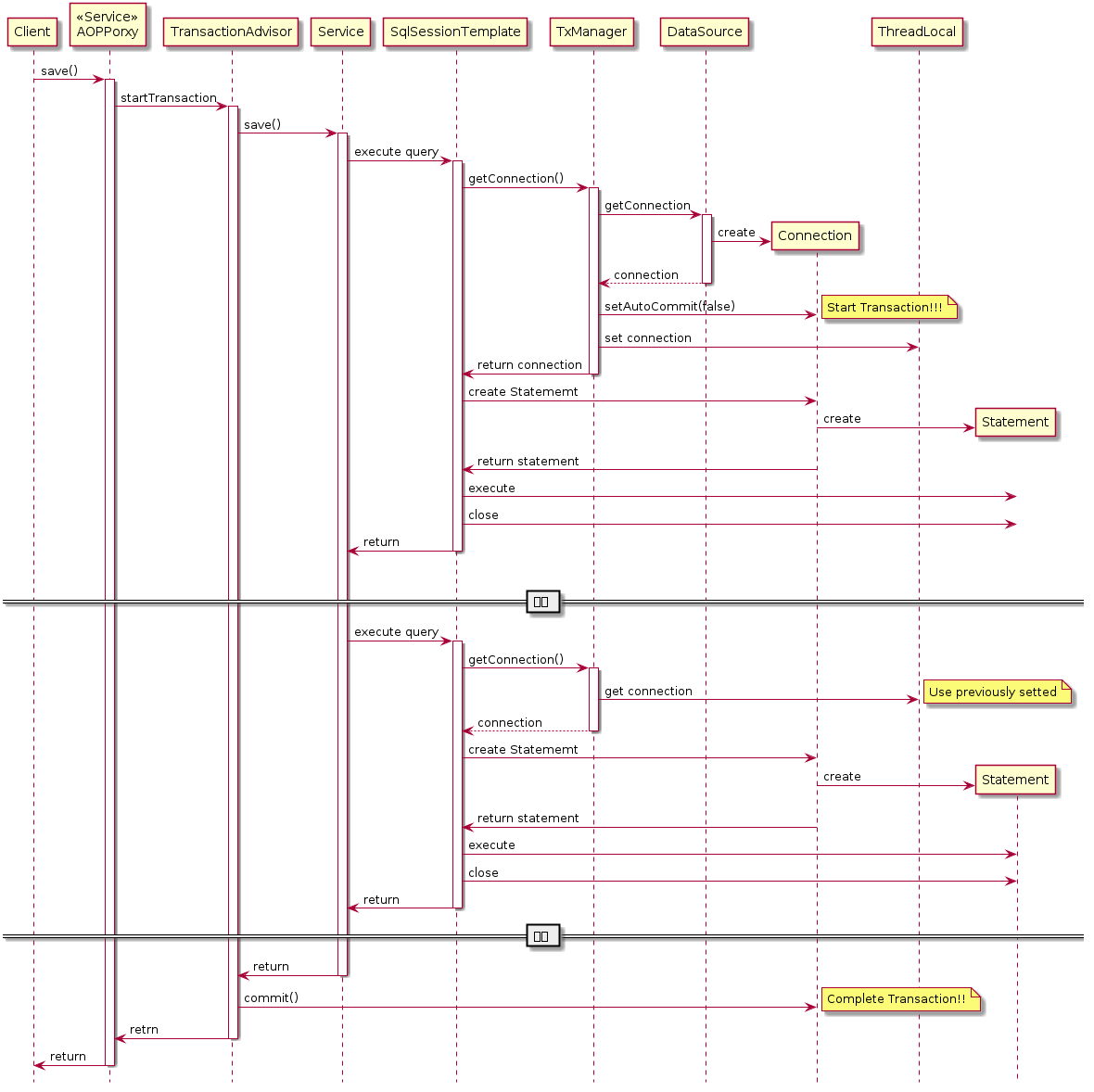
PlatformTransactionManager(이하 TxManager)는 기본적으로 Thread 에 연결된 Stack 기반의 Connection 제공자 입니다.
갑자기 어렵게 느껴지시는 분들을 위해 간략하게 설명 하겠습니다.
6.3.1. "Thread에 연결된"
TxManager는 언제나 현재 쓰래드와 연결이 됩니다. 왜냐하면 ThreadLocal을 이용하여 Connection을 관리하기 때문입니다.
(Note: ThreadLocal은 하나의 변수처럼 선언 되지만 현재 실행되는 Thread마다 다른 값을 저장할수 있는 Java의 core API입니다.)
Class TxManager {
Static ThreadLocal<Connection> currentConnection;
Public Connection getConnection() {
return currentConnection.get();
}
Public void setConnection(Connection conn) {
return currentConnection.set(conn);
}
}
이렇게 TxManager 가 ThreadLocal 을 이용해 연결 관리를 수행한다는 것은 Transaction은 하나의 쓰래드에서 시작하고 종료되어야 한다 라는 것을 의미합니다.
이것은 또 다시 Batch등에서 성능을 위해 Multi Thread 화 했을때 트랜잭션은 각 쓰래드 별로 실행되게 설계 해야 한다는 제약 으로 이어집니다
6.3.2. "Stack 기반의"
이 이야기를 이해 하기 위해서는 분리된 트랜잭션을 먼저 알아야 합니다.
하나의 트랜잭션이 수행되던 도중에 현재 트랜잭션과 별개로 무조건 commit 되어야 하는 트랜잭션이 필요할때가 있습니다.
보통 이력성 트랜잭션이 이런 요구가 있습니다. 대표적으로 주문을 수행하면서 주문의 성공 여부와 별개로 주문 처리 과정에 대한 이력을 DB로 남겨야 할때등이 대표적이죠.
이럴 때 현재 트랜잭션인 주문과는 분리된 주문 이력 저장 트랜잭션이 필요하게 됩니다. (멀티 쓰래드의 경우와는 다릅니다.)
Spring에서는 propagation = Propagation.REQUIRES_NEW 옵션을 통해 분리된 트랜잭션을 실행시킬수 있습니다.
@Component
class OrderService {
@Autowired OrderHistoryService orderHistoryService;
@Transactional
public void order() {
jdbcTemplate.executeQuery("select 1 from dual");
orderHistoryService.recordOrderComplete();
jdbcTemplate.executeQuery("select 1 from dual");
}
}
@Component
class OrderHistoryService {
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void recordOrderComplete() {...}
}
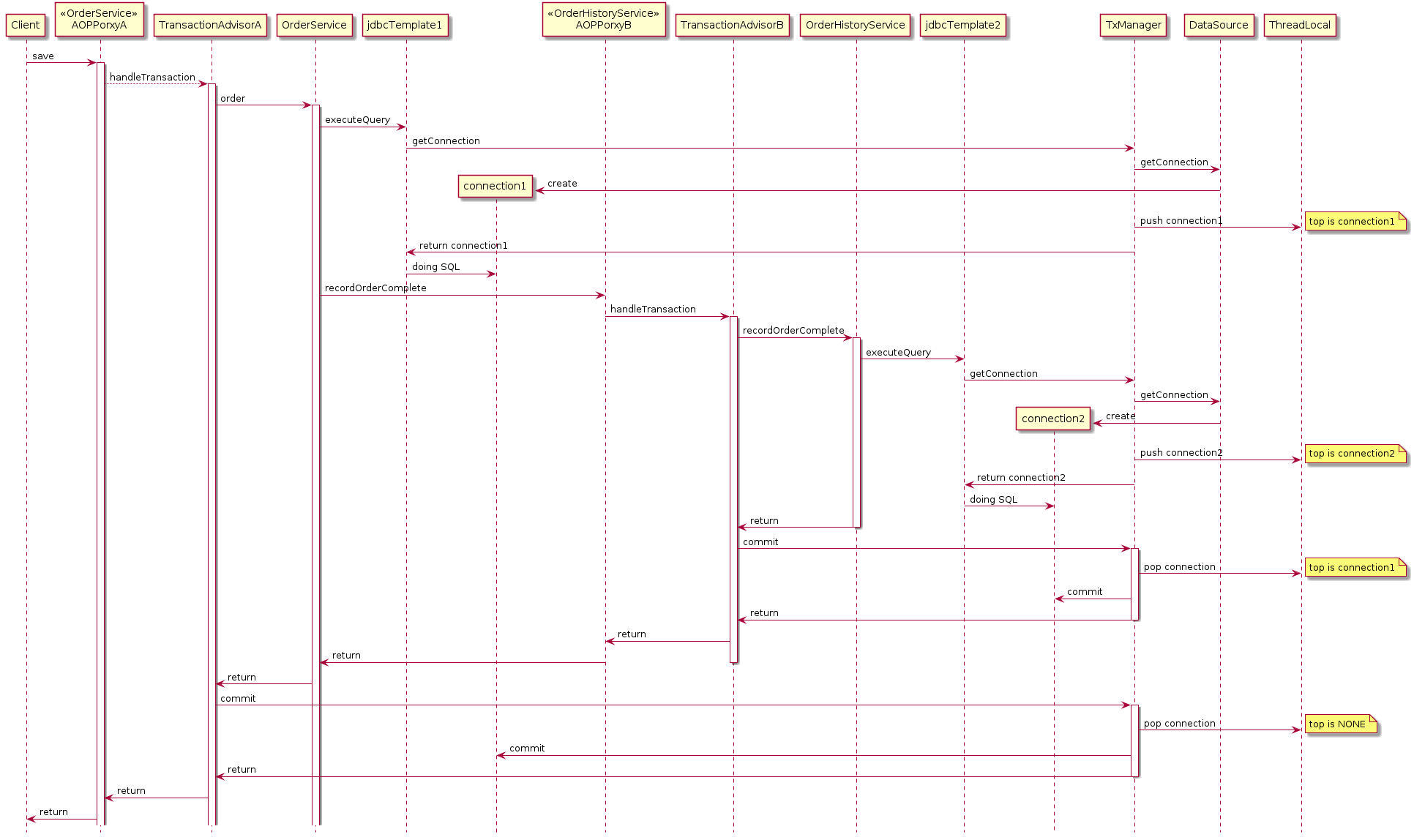
그림: Proxied bean이 또 다른 Proxied bean을 호출하면서 TxAdvice가 여러번 실행되는 그림
이렇게 새로운 @Transactional 이 나옸을때 REQUIRED_NEW등 분리된 트랜잭션을 요청하게 되면 TxManager는 기존의 Connection을 ThreadLocal의 stack에 넣어 보관해두고 새로운 Connection을 ThreadLocal에 지정합니다.
(물론 Stack도 ThreadLocal로 관리 되기 때문에 현재 쓰래드에 연결됩니다)
이를 통해 propagation = Propagation.REQUIRES_NEW 를 가진 메소드를 실행하는 도중에는 새롭게 만들어진 Connection을 이용하여 동작하며 해당 메소드를 빠져나올때 Commit/Rollback 하게 됩니다.
빠져 나온후에는 Stack에서 기존에 사용하던 Connection을 pop 해와서 ThreadLocal에 지정하여 기존의 트랜잭션을 이어가게 됩니다.
6.3.3. "Connection 제공자"
TxManager는 기본적으로 하나의 DataSource 를 점유하여 Connection을 요청하는 API (JdbcTemplate, SqlSessionTemplate 등등) 에게 Connection을 제공하는 Factory 및 Provider 역활을 수행합니다.
각각의 API에서 직접 Connection 을 생성하지 않고 TxManager에게 요청하기 때문에 트랜잭션을 관리할수 있는 것입니다.
만약 DataSource나 Driver를 통해 직접 Connection을 획득하여 사용한다면 Spring이 제공하는 Transaction Management에서 벗어나게 되는 것입니다.
7. Global Transaction
7.1. Global Tx 개요
Local Transaction은 하나의 Datasource 에서 발생하는 자체적인 트랜잭션만 관리하는 것입니다. 국지적인 트랜잭션이라 Local이라고 부릅니다.
Global Transaction은 여러개의 Datasource에서 발생하는 트랜잭션을 관리하는 것입니다. 전역적인 트랜잭션이라 Global이죠.
여러 data source (복수의 DB 연결, JMS등등) 에서 작업을 수행하고 전체 작업을 commit 하거나 rollback할수 있게 하는것을 의미합니다.
Global Tx를 달성하는 방식에는 여러 방식이 있고 그중 J2EE에서 표준으로 채택한 것은 X/Open의 XA 표준입니다. ( eXtented Architecture 의 약자입니다)
이표준에 따랐기 때문에 JDBC에서 XADatasource라는 명칭을 사용하는 것이죠,
XA 표준은 2단계 커밋(2-phase commit) 을 이용해 global tx를 수행하는 표준입니다.
Local Tx는 1 phase commit을 수행합니다.
Begin Tx Work Work Work end Commit
XA 표준에 따른 2 phase commit는 다음과 같이 동작합니다.
Begin tx - data source 1 Begin tx - data source 2 Work on ds 1 Work on ds 2 End ds 1 End ds 2 Prepare ds 1 Prepare ds 2 Commit ds 1 Commit ds 2
Prepare 중 하나라도 실패한다면 모든 DS는 begin 이전의 상태로 rollback 되어야 합니다. (이런 의미에서 보면 2PC에서 prepare는 1PC에서의 commit과 유사하죠)
이런 복잡한 과정을 거쳐야 하기 때문에 Global Tx는 성능이 상당히 떨어지게 됩니다. 따라서 Global Tx를 활성화 할때는 성능 요구사항을 잘 판단해야 합니다.
7.2. Global Tx in Spring
개념을 이해했으니 이제 프로그래밍의 영역으로 가보겠습니다.
먼저 경고 사항부터 나갑니다.
"DataSource" 1개 당 Tx Manager는 1개 입니다 서로 다른 DataSource는 서로 다른 Tx Manager에 의해 관리 됩니다. 트랜잭션은 같은 TxManager를 사용하는 경우에만 유효합니다.
이 당연한 것을 쓴거 같은 문장이 경고인 이유는 다음에 설명하는 내용을 통해 이해하시게 될것입니다.
우선 J2EE에서 Global Tx를 처리하는 방법부터 설명하겠습니다.
J2EE에서는 XA Datasource로 선언된 Data Source는 전체를 하나의 DataSource로 취급합니다.
각각은 별도의 시스템으로 연결된 Datasource이지만 하나의 XADatasource로 취급되어 트랜잭션을 commit 하면 전체 xa datasource에 대해 prepare-commit을 수행합니다.
이 이야기는 XA Datasource 들에 대해서 단 하나의 TxManager가 사용된다는 것입니다.
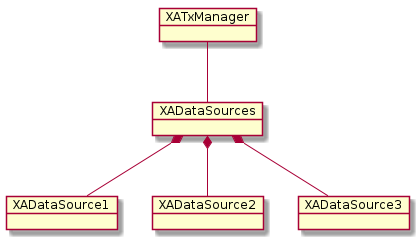
그림: 1-1-n
TxManager 1개에 XA Datasource(Composite) 1개.
큰 문제는 없어 보이죠?
그런데 환경적으로 datasource가 증가되어 2개 이상인데, 모든 Datasource를 XA Datasource로 등록하지 못하는 경우가 있습니다. XA를 지원하지 않는 DB라던가, 성능 문제때문에 XA를 사용할수 없는 경우라던가, XA에 과정에서 오류가 발생한다던가….
하지만 그런 Datasource에서도 Tx는 지원해야 합니다. 따라서 Tx Manager가 여러개가 Spring context에 등록 될 수 있습니다.
스프링에서는 이런 환경에서 어떤 Tx Manager를 이용해 Transaction을 처리할것인가를 지정할수 있습니다.
@Transactional(txManager=‘txManager1")
public void action(){ ... }
이제 부터 문제가 복잡해 집니다.
Local Tx 인 DS와 Global Tx인 DS를 동시에 사용하면 어떻게 될까요? 서로 다른 Local Tx DS를 동시에 사용하면 어떻게 될까요?
이제 처음의 경고 문장을 다시 보면 그 문장이 경고인 이유를 아실수 있을 겁니다.
"DataSource" 1개 당 Tx Manager는 1개 입니다 서로 다른 DataSource는 서로 다른 Tx Manager에 의해 관리 됩니다. 트랜잭션은 같은 TxManager를 사용하는 경우에만 유효합니다.
이런 문제는 쉽게 해결 되지 않으며 섬세한 설계를 요구하고, 쉽게 오류를 낼수 있기 때문에 주의깊게 확인하면서 프로그래밍 해야 합니다.
이때 적용할수 있는 기본적인 설계 주의사항이 몇개 있습니다.
-
비니지스 로직 설계시에 여러 DS에 동시에 접근하는 경우를 최소화 한다.
-
분리된 트랜잭션을 적절히 사용한다
-
같은 Datasource를 사용하는 코드끼리 묶어서 메소드를 만든다
-
가급적 하나의 Bean 안에서는 같은 TxManager를 사용하는 코드로만 구성한다
반대로 Local Tx Manager인 상태에서 여러 Datasource를 사용하게 되면, 단 하나의 Datasource에 대해서만 commit 이 수행되게 됩니다.
@Transactional(txManager="dataSource1TxManager")
public void doSomethin() {
insertIntoDataSource1(); // commit 됨
insertIntoDataSource2(); // 커밋 될지 알수 없음. autoCommit 설정에 따라 트랜잭션 설정과 무관하게 바로 커밋될수 있습니다
}
위의 경우 datasource2 의 커넥션 풀이 소진되어 서비스 장애로 이어질수도 있습니다.
이 문제는 PlatformTransactionManager 의 실제 구현을 어떤것을 사용하느냐에 따라 현상이 달라집니다.
컨테이너의 기능을 활용하게 되는 JtaTransactionManager를 사용하게 되면 발생하지 않을수 있습니다. 하지만 DatasourceTransactionManager를 사용하면 발생합니다. PlatformTransactionManager의 구현체가 매우 많기 때문에 특정 구현을 잘 선택하여야하고, 프로그래밍시에는 가급적 특정 PTM에 의존하지 않게 개발하시는게 좋습니다.
java
transaction
spring